非负L₁逼近多项式的存在性与最优度数
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | A Note on Non-Negative L1-Approximating Polynomials |
| 作者 | Jane H. Lee, Anay Mehrotra, Manolis Zampetakis |
| 机构 | Yale University, Stanford University, Yale University |
| 论文地址 | https://arxiv.org/abs/2605.08072 |
| 发表时间 | 2026年5月 |
一句话概要
本文研究标准高斯分布下非负L1逼近多项式的存在性问题。
作者证明:任何高斯表面积有界(Γ ≤ Γ_H)的集合类,
其指示函数存在度数不超过O(Γ_H²/ε² · log(1/ε))的非负多项式逼近,
该界与不要求非负性时已知的最优度数界仅差常数因子。
这一结果意味着非负L1逼近本质上并不比普通L1逼近更难获得。
背景与研究动机
低度多项式逼近是计算学习理论中的核心工具。论文指出,它在经典L1回归算法、不可知学习以及近年兴起的可测试学习等分布学习问题中均有广泛应用。在标准高斯分布下,研究者主要关注三种不同强度的多项式逼近概念:
- 普通L1逼近:多项式在L1范数下逼近指示函数,但对多项式在点态上的取值范围不做任何限制。
- 夹逼多项式:存在一对多项式 (p_{\text{down}}) 和 (p_{\text{up}}),使得 (p_{\text{down}}(x) \le \mathbf{1}H(x) \le p{\text{up}}(x)) 处处成立,且两者期望差距很小。这是一种极强的点态约束。
- 非负L1逼近:多项式在L1范数下逼近指示函数,且其值域被限制在 ([0, \infty)) 内,但不需要处处大于或小于指示函数。
作者指出,非负L1逼近的强度介于普通L1逼近和夹逼多项式之间。这一概念近期在仅有正例的平滑学习问题中找到了直接应用:这类学习算法需要多项式逼近且有一侧值域约束,但并不需要完整的夹逼对。论文进而提出一个问题:是否存在通用的、与普通L1逼近同样高效的非负L1逼近构造方法?
现有方法的瓶颈
论文围绕现有研究的局限展开以下分析:
第一,夹逼多项式的构造代价过高且适用范围有限。 夹逼多项式虽然能自然给出非负L1逼近(因为上夹逼多项式自动是非负的),但已知的夹逼构造仅对少数具有低内在维度的集合类有效。对于更一般的有限高斯表面积集合类,是否普遍存在夹逼多项式仍然是开放问题。这意味着依赖夹逼来获得非负逼近是一条受限的路径。
第二,普通L1逼近缺乏点态约束,无法直接用于需要范围限制的场景。 在不可知学习和可测试学习中,普通L1逼近多项式已足够好用。但作者提到,在最新的正例平滑学习框架中,算法要求逼近多项式具有非负性或更低界约束。普通L1逼近多项式可能取负值,因此不能替代上述角色。
第三,现有的一侧逼近(one-sided approximation)概念与本文目标不对齐。 可靠学习文献中提出的正侧逼近多项式和负侧逼近多项式,要求对指示函数的正侧和负侧施加不对称的点态控制。例如,当 (f(x) = 1) 时,多项式值须落在 ([1 - \varepsilon, \infty))。经仿射缩放后,这类多项式在布尔超立方体上的取值可能接近零,但不一定在连续分布空间上保持非负,且它们本质上是点态约束而非平均约束。论文明确指出,两种概念不可相互推论。
第四,高斯表面积框架下的已知上界尚未被用于非负逼近。 Klivans、O’Donnell和Servedio的工作以及Pesenti、Slot和Wiedmer的近期工作已经给出了高斯表面积有限类的最新L1逼近度数上界。但这些构造并未考虑多项式值域的非负性,因此不能直接用于需要非负约束的新场景。
核心洞察与贡献
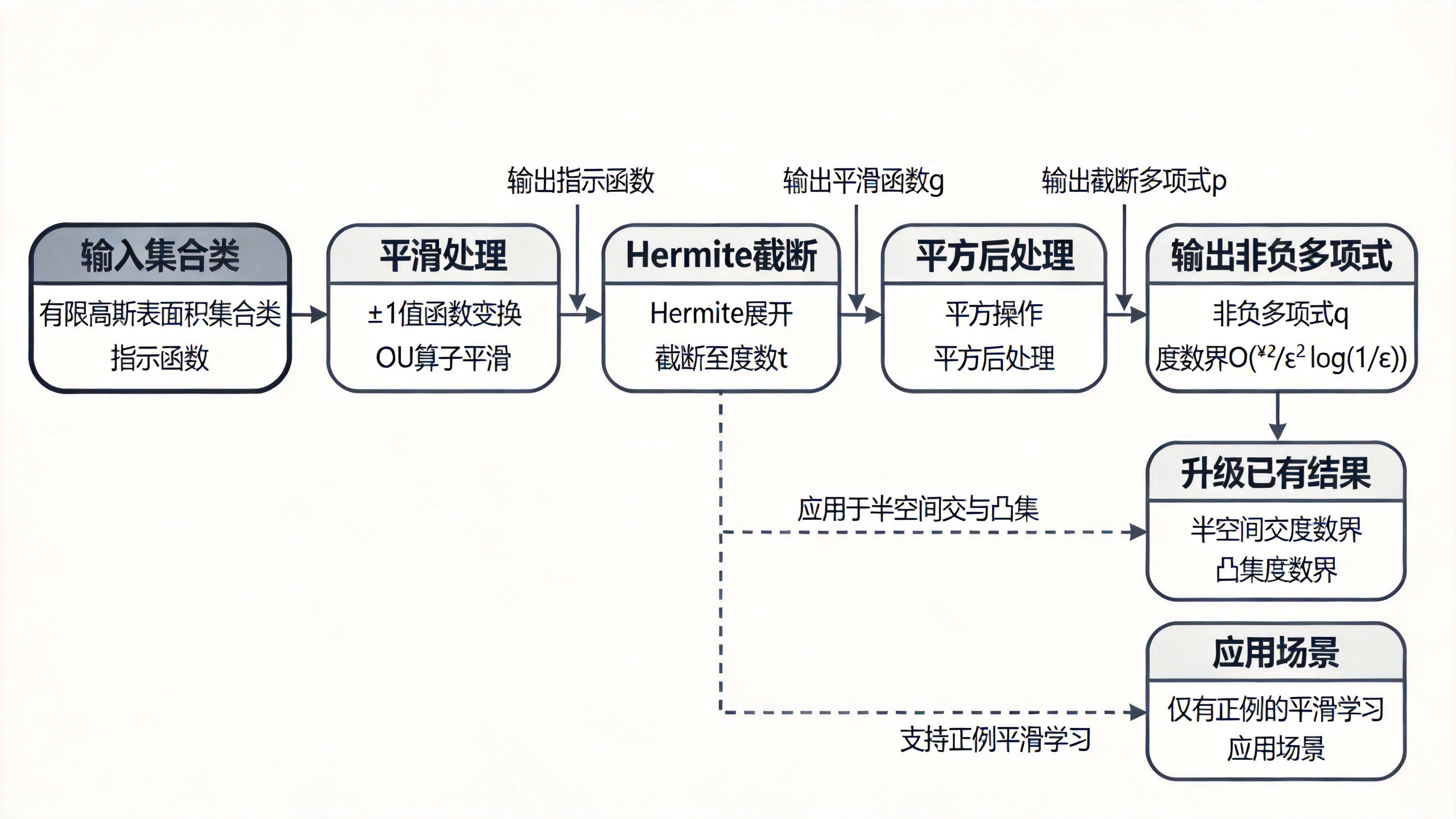
核心洞察:作者观察到,如果从现有的L1逼近多项式出发进行适当的后处理,可以在几乎不增加度数的情况下获得非负性,而且这个后处理步骤在通用性上不损失逼近精度。具体而言:令 (p) 为通过截断Hermite展开获得的逼近多项式,则后处理项 (q = (1 + p)^2 / 4) 保持了逼近性能,同时保证了在整个 (\mathbb{R}^d) 上非负。
具体贡献(每条对应前述瓶颈中的一条局限):
-
证明有限高斯表面积足以保证非负L1逼近的存在性,且不要求集合类具备其他结构性质。这绕过了夹逼多项式适用范围窄的限制,为更一般的集合类提供了非负逼近的通用保证。
-
构造的度数界与不要求非负性的普通L1逼近的最佳已知度数界匹配至常数因子。具体来说,度数上界为 (O\left(\frac{\Gamma_H^2}{\varepsilon^2} \log\frac{1}{\varepsilon}\right)),与Klivans等人的经典结果在量级上一致。这意味着非负约束并未引入本质性的额外代价。
-
算法上给出了一个显式构造:基于Hermite展开的截断与平方处理。这与纯粹的存在性证明不同,可以提供可操作的构造路径。
-
将已有结果(如半空间交、凸集的度数界)直接升级为非负版本。例如,m个半空间交的非负逼近度数上界为 (O\left(\frac{\log^2 m}{\varepsilon^2} \log\frac{1}{\varepsilon}\right)),凸集的非负逼近度数上界为 (O\left(\frac{\sqrt{d}}{\varepsilon^2} \log\frac{1}{\varepsilon}\right))。
方法详解
论文的构造分为三个步骤:平滑、截断与后处理。以下详细展开每个步骤的动机和形式。
步骤1:平滑。 定义 (h(x) = \mathbf{1}H(x)),以及 (f(x) = 2h(x) - 1),将指示函数映射为 ({\pm 1})-值函数。利用Ornstein–Uhlenbeck算子 (T\rho) 对 (f) 进行平滑:
[ g(x) = T_\rho f(x) = \mathbb{E}_{Z \sim \gamma_d} \left[ f\left( \rho x + \sqrt{1 - \rho^2} Z \right) \right] ]
动机:平滑操作将硬分类边界软化,使函数变得可被低度多项式有效逼近。参数 (\rho \in [0, 1]) 控制平滑程度:(\rho) 越接近1,平滑越弱,函数越接近原始指示函数;(\rho) 越小,平滑越强,函数越光滑但偏离原始函数越远。关键引理(Lemma 2)指出,平滑带来的 (L_1) 误差以 (\rho) 为参数受控于高斯表面积:
[ |f - g|_{L_1(\gamma_d)} \le 2\sqrt{\pi},\Gamma(H)\sqrt{1 - \rho} ]
步骤2:截断Hermite展开。 对 (g) 进行Hermite多项式展开,并截断至度数不超过 (t) 的项,得到 (p = \Pi_{\le t} g)。由于Hermite基是标准高斯测度下的正交基,截断的意义在于保持 (L_2) 逼近精度。Lemma 2给出:
[ |g - p|_{L_2(\gamma_d)} \le \rho^{t+1} ]
动机:平滑后的函数 (g) 的Hermite系数随度数衰减,衰减速度由 (\rho) 控制。截断到度数 (t) 保留主要能量,丢弃高阶项。这里没有使用非负约束而是直接使用正交投影,是因为后续的平方步骤会将符号约束转化为范围约束,因此不需要在投影步骤引入额外的正则化。
步骤3:后处理得到非负多项式。 定义:
[ q(x) = \frac{1}{4}\bigl(1 + p(x)\bigr)^2 ]
动机:平方操作确保 (q(x) \ge 0) 对于所有 (x \in \mathbb{R}^d) 成立,即值域包含于 ([0, \infty))。度数翻倍为 (2t),但这个常数因子被整体界吸收。作者通过以下链条控制误差:
[ |q - h|{L_1(\gamma_d)} \le |p - g|{L_2(\gamma_d)} + |f - g|_{L_1(\gamma_d)} \le \rho^{t+1} + 2\sqrt{\pi},\Gamma(H)\sqrt{1 - \rho} ]
整个证明的关键在于利用 (g) 的值域约束 (g(x) \in [-1, 1])(因为它是 ({\pm 1})-值函数在OU算子下的平均)和 (p) 的 (L_2) 范数有界性来建立不等式链,将平方后的误差还原为已知的平滑和截断误差。
参数选择:设 (\rho = 1 - \min\left(1, \frac{\varepsilon^2}{16\pi \Gamma(H)^2}\right)),使 (2\sqrt{\pi},\Gamma(H)\sqrt{1 - \rho} \le \varepsilon/2);再选最小整数 (t) 满足 (\rho^{t+1} \le \varepsilon/2)。由此得到 (t = O\left(\frac{\Gamma(H)^2}{\varepsilon^2} \log\frac{1}{\varepsilon}\right)),从而 (\deg(q) = 2t = O\left(\frac{\Gamma(H)^2}{\varepsilon^2} \log\frac{1}{\varepsilon}\right))。
文献分析与评估
这篇论文属于理论证明类短文,不包含传统意义上的实验,因此本章评估其论证结构和文献定位。
分类框架是否合理。论文将多项式逼近的三个层次——普通L1逼近、非负L1逼近、夹逼多项式——之间的关系刻画得清晰且自洽。可以理解为,这一三阶框架揭示了逼近强度与构造难度之间的递进关系。论文的核心主张是第二层次在标准高斯分布下并不比第一层次更难,这一主张的逻辑链条完整,且由定理1的证明所支撑。作者没有声称非负逼近与夹逼一样强,而是刻意说明其弱于夹逼但强于普通逼近,这一边界界定是恰当的。
文献覆盖是否全面。论文引用了Klivans等人的经典工作(KOS08)、Pesenti等人近期的度数改进结果(PSW26)、以及夹逼多项式的最新进展(KSV26)。可靠学习方面引用了Kalai等人和Kanade、Thaler的工作。正例平滑学习的应用背景引用了作者自身即将发表的STOC 2026工作(LMZ26)。参考覆盖了从经典(Ball 1993)到最新(2026年)的关键工作,与研究短文的形式相符。唯一未充分讨论的点是:作者未对非高斯分布下的情况进行系统性文献梳理,但这是论文明确承认的未来方向,因此可以理解为刻意限定于高斯情形。
批判性观点是否有据可查。论文在讨论部分明确承认,对于同样为有限高斯表面积的集合类,是否普遍存在夹逼多项式是不可知的。这一承认是谨慎且诚实的,因为它直接约束了本文结果与夹逼多项式之间的关系。论文还指出,非负逼近与可靠学习中的一侧逼近概念不可比较,并给出了具体理由(一个为平均约束,一个为点态约束)。这些判断都基于严格的文献对比和定义分析,可信度高。
论证深度。定理1的证明从引理2(源自KOS08和PSW26)出发,通过代数变形和Cauchy-Schwarz不等式建立了三项误差界。这个证明并非独创性极高——作者自己也表示这本质上是"观察"到已知构造的后处理即可得到非负性——但正是这种简洁性构成了论文的价值:它展示了已存在结果与未预料应用之间的桥梁。
优势与局限性
优势:
-
紧致性。论文证明,非负约束下的度数上界与不要求非负时的最优界仅差常数因子,说明非负性在标准高斯分布下几乎是"免费"的。这一结论对于理论研究者来说是令人满意的。
-
构造显式。不同于纯粹的存在性证明,论文给出的多项式构造基于可计算的Hermite展开和截断,因此原则上可直接用于算法实现。
-
适用范围广。结果对任何有限高斯表面积的集合类通用,不要求集合具有凸性、连通性等结构性质。这意味着结果覆盖了半空间交、凸体、以及更广泛的拓扑复杂度有限的集合。
局限性:
-
仅限于标准高斯分布。论文的证明强烈依赖高斯测度的特殊性质——特别是Ornstein–Uhlenbeck算子的谱属性、Hermite基的正交性以及高斯表面积的几何意义。推广到均匀分布或在更宽的分布族上是否成立,尚未可知。作者自己也承认,将这种普适性推广到非高斯情形是一个开放问题。
-
度数的常数因子未被精细刻画。论文给出的界为 (O\left(\frac{\Gamma_H^2}{\varepsilon^2} \log\frac{1}{\varepsilon}\right)),作者指出此界与已知最优界"至多常数因子"差距。但这个常数因子具体有多大(如2倍、4倍还是更大)并未显式给出,对于实际应用中的度数敏感性,这一信息值得进一步研究。
-
非负逼近是否能在现有框架之外获得更紧的界尚未可知。论文的证据表明,当前构造不劣于普通逼近,但并未排除进一步改进的可能性。
-
可复现性评估:论文无需代码或数据,理论证明完全自包含,关键引理引用了已发表文献,复现论证所需的前置知识齐全。
未来方向与开放问题
论文在讨论和结语中提出几个具体方向:
第一,理解三种逼近之间的完整关系。论文明确提出"理清普通L1逼近、非负L1逼近与夹逼多项式之间的差距是一个有趣的方向"。具体来说,是否存在有限高斯表面积但不存在任何低度夹逼多项式的集合类?非负逼近的存在是否在某些条件下等价于夹逼逼近的存在?这些问题的回答将深刻影响多项式逼近理论的图景。
第二,非高斯分布的推广。论文的关键工具(OU算子、Hermite基)是高斯分布特有的。在其他常用分布(如各向同性对数凹分布或更一般的测度)下,是否也能在非负性和度数代价之间取得类似的平衡?可能的方法包括寻找适用于该分布的正交基和对应的平滑算子。
第三,更宽泛的构造机制的刻画。是否还存在其他后处理技巧,可以同时保证非负性和更紧的逼近误差?平方操作是一个简单后处理,但可能会引入不必要的误差因子,是否存在通过凸优化直接构造非负多项式的方法可以得到更优度数?
第四,在算法和样本复杂度层面的影响。作者引用正例平滑学习作为应用,但论文并未分析此逼近结果对学习算法的样本复杂度或运行时间的影响推导。可以预期,这一结果将直接改善正例平滑学习框架的度数正则项,进而优化学习复杂度。这一方向值得进一步定量展开。
组会预判问答
Q1: 这个结果是否可以扩展到均匀分布?
回答:论文的方法强烈依赖标准高斯测度的结构——特别是Ornstein–Uhlenbeck算子的谱分解性质和Hermite基的正交性。对于均匀分布(如单位球或单位超立方体),上述工具不可用,需要使用不同类型的正交多项式(如Legendre多项式或Chebyshev多项式)和对应平滑算子。是否也能得到类似的非负性和度数界尚属开放问题。论文在讨论部分明确指出了这一限制。
Q2: 非负逼近多项式的实际构造复杂度如何?是否可以在多项式时间内计算?
回答:构造步骤包括:(1) 计算OU平滑 (g = T_\rho f)——这需要求高维高斯积分,一般通过蒙特卡洛方法近似;(2) 对 (g) 进行Hermite展开截断,即计算前 (t) 个Hermite系数。对于任意集合 (H),这两个步骤的计算复杂度取决于集合的描述方式。对于半空间或半空间交等代数结构,Hermite系数可以用闭式计算;对于一般Borel集,可能需要采样或近似方法。论文未讨论计算复杂度,但此构造本质上是"信息论存在性"而非"计算可行性"保证。
Q3: 当 (\Gamma(H) = 0) 时,定理1给出 (t = 0) 的常数多项式。此时常数多项式如何逼近一个非平凡的指示函数?
回答:论文指出,当 (\Gamma(H) = 0) 时,集合 (H) 的高斯测度必为0或1。证明中取 (\rho = 0),此时 (g = T_0 f = \mathbb{E}[f]) 退化为常数,进而 (q = \frac{1}{4}(1 + \mathbb{E}[f])^2) 也是常数,逼近误差为零。可以理解为,零点高斯表面积的集合——如一个点的补集——要么几乎全覆盖要么几乎为空,常数多项式足以精确逼近。这一边界情形在技术上合理。
Q4: 夹逼多项式和非负L1逼近在应用上的核心差异是什么?什么场景下非负逼近不够用?
回答:夹逼多项式提供的点态控制比非负逼近更强:它保证多项式处处位于指示函数两侧,而非仅在平均意义上接近。在需要逐点可靠性保证的场景——例如安全关键系统中的决策规则验证、或其他无法容忍任意点大偏差的推理任务——夹逼多项式是必要的,而非负逼近不够。论文引用的正例平滑学习则属于可以容忍小范围违反点态约束的任务,因而非负逼近足够。
本报告由立理AI生成,仅供参考,请以原文为准。