CPR: 路径级校准的可信知识图谱问答
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Conformal Path Reasoning: Trustworthy Knowledge Graph Question Answering via Path-Level Calibration |
| 作者 | Shuhang Lin*, Chuhao Zhou*, Xiao Lin, Zihan Dong, Kuan Lu, Zhencan Peng, Jie Yin\†, Dimitris N. Metaxas\† |
| 机构 | Rutgers University, Independent Researcher, UIUC, The University of Sydney |
| 论文地址 | arXiv:2605.08077v1 |
| 发表时间 | 2026-05-08 |
一句话概要
知识图谱问答(KGQA)需要统计可保证的预测集,但现有共形预测方法因采用跳级校准而违反可交换性假设,导致覆盖保证失效且预测集过大。本文提出CPR框架,核心洞察是将校准单位从逐跳提升至逐路径,利用查询级独立性恢复可交换性,并通过PUCT引导的轨迹收集训练残差共形值网络(RCVNet)学习判别性路径分数。实验表明,CPR在两个基准上相比共形基线将经验覆盖率提升34%,同时将平均预测集大小缩小40%,实现了有效且紧凑的覆盖保证。
背景与研究动机
知识图谱以结构化的实体-关系三元组表示真实世界事实,支持可解释的多跳推理。在医疗诊断或金融风险评估等高风险场景中,仅返回单一确定性答案是不够的,因为这无法建模关系型知识图谱中固有的模糊性,也无法为可靠性评估提供严格基础。因此,需要一种能够输出集合式预测的推理框架,并在用户指定的风险水平下统计保证预测集包含真实答案。
共形预测(Conformal Prediction, CP)提供了一种无分布假设的框架,能在有限样本下构造预测集并给出覆盖率保证。近期研究已将CP引入图领域,包括知识图谱嵌入、图神经网络节点分类等。这些方法主要局限于原子级节点级断言的验证,而非复杂的推理链。另一种思路是通过概率嵌入或LLM生成的置信度隐式建模不确定性,但缺乏严格的统计保证。UaG是将CP集成到KGQA的重要尝试,它采用逐组件(包括图遍历和LLM评估)的阶段式共形流水线——这一跳级校准策略正是本文要解决的核心问题。
现有方法的瓶颈
论文将CP扩展到多跳KGQA时识别出两个根本性挑战:
跳级校准引入顺序依赖,违反可交换性。 CP的统计保证建立在可交换性假设之上:校准样本与测试样本应来自同一分布且在置换下不变。当CP在逐跳图遍历过程中应用时,第k步的预测集决定了第k+1步可达的实体,这形成一个马尔可夫依赖链:S₁→C₁→S₂→…。具体而言,第k步的校准分数Sₖ(i)依赖于前一步的预测集Cₖ₋₁(i),而Cₖ₋₁(i)本身又由全部校准样本的阈值决定,导致Sₖ(i)跨样本纠缠。论文以"《盗梦空间》导演在哪里学习"为例说明:如果跳1预测集排除了克里斯托弗·诺兰,那么无论后续如何设阈值,正确答案伦敦大学学院(UCL)都无法到达。这意味着跳级校准从根本上破坏了可交换性,仅靠改进评分无法从内部修复。
非判别性评分导致预测集过大。 即使忽略可交换性,共形预测的集效率取决于非符合分数(nonconformity score)的判别质量。仅基于局部实体相似性的分数无法捕捉多跳推理中的路径级相关性。为了满足覆盖率要求,共形机制只能采用过度保守的分位数,产生超大预测集——这在高斯动作导向型问答中缺乏实际效用。
值得注意的是,这两条局限构成因果关系:跳级校准破坏了理论前提,非判别性评分放大了实际代价。但论文进一步观察到一个关键不对称:路径内部虽相关,不同查询之间却是独立同分布样本——这为路径级校准保留了可交换性基础。
核心洞察与贡献
核心洞察在于:校准单位和评分机制需要同时重新设计。对于校准,跳级方法因共享中间节点和局部邻域而产生顺序依赖;相比之下,来自随机划分的校准集和测试集的查询在构造上就是可交换的(查询独立性)。因此,应转向路径级校准。对于评分,局部语义相似度不足以捕捉路径级正确性,需要一种可学习的机制来捕获全局路径连贯性以改进候选区分度。
基于此,论文提出Conformal Path Reasoning (CPR),主要贡献包括:
- 查询-可交换的路径级共形校准:通过将多跳推理过程封装为每条查询的路径级分数,CPR绕开了关系依赖,在查询层面保持可交换性,实现有效的共形保证。这一贡献直接回应了跳级校准违反可交换性的瓶颈。
- 学习型判别性路径评分:引入残差共形值网络(RCVNet),通过PUCT收集的轨迹学习区分正确路径与看似合理但错误的路径,在保持有效覆盖率的同时获得更紧凑的预测集。这一贡献直接回应了非判别性评分导致集过大的瓶颈。
- 实证改进:在WebQSP和CWQ上的实验表明,CPR显著优于现有共形基线,以更小的预测集实现了更高的有效覆盖率。实验证据使前两条贡献从理论走向可验证。
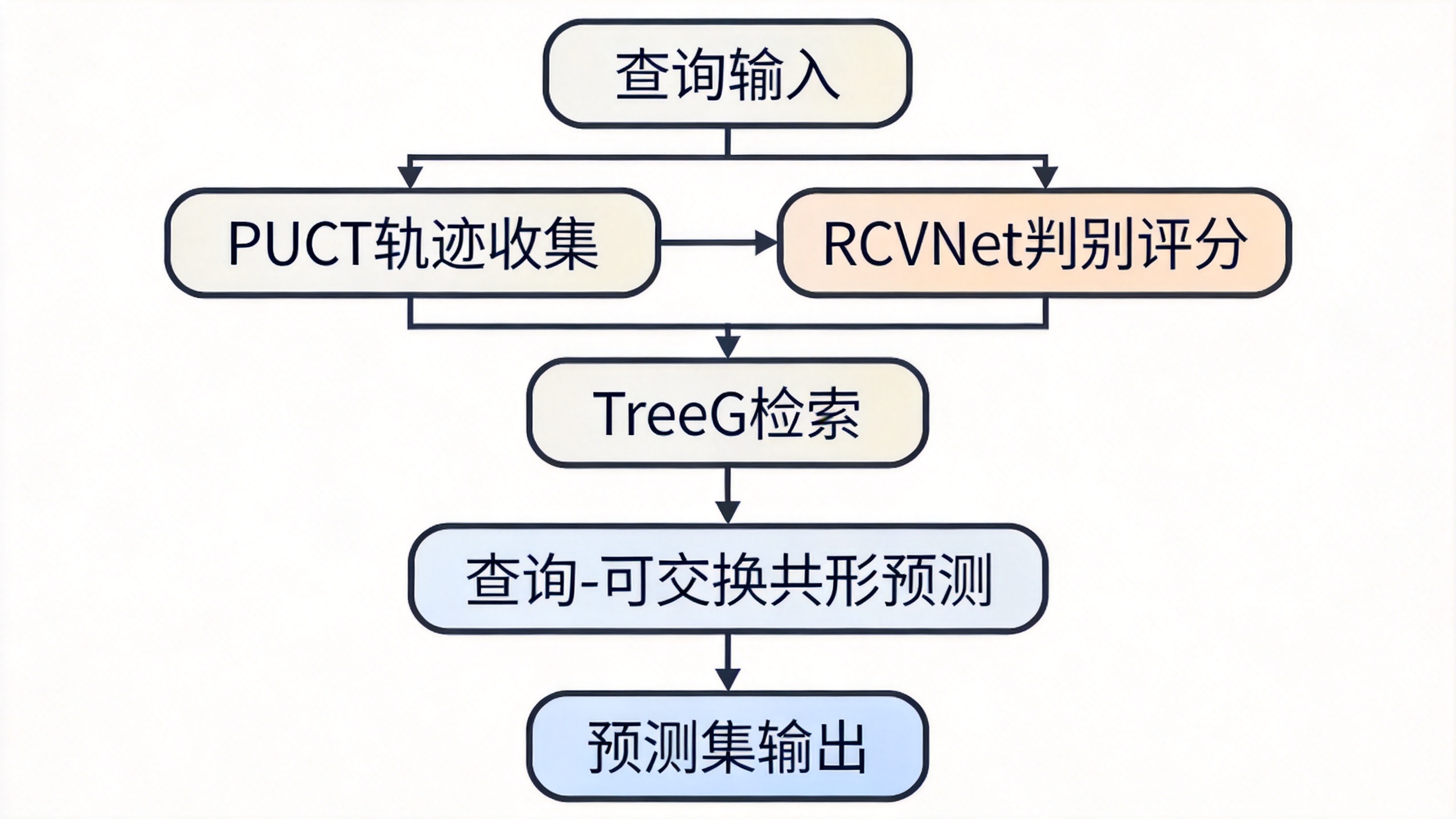
方法详解
CPR包含两大组件:判别性路径评分机制和查询-可交换共形预测。前者为后者提供区分度高的非符合分数,后者负责提供统计保证。
判别性路径评分机制
动机:简单局部相似度无法区分正确路径与看似合理但错误的路径,需要学习全局判别信号。但多跳KGQA中缺少大量的地面真实路径作为训练数据。因此论文设计PUCT驱动的轨迹收集来构建高质量正负路径对,训练RCVNet学习判别性分数。
PUCT引导的轨迹收集:采用Predictor + UCT(PUCT)作为轨迹收集器,主要有两个优势:其探索奖励会鼓励访问欠探索的关系,从而生成语义上看似合理但错误的负路径;同时探索过程积累的关系级统计信息可作为结构先验。具体地,PUCT从主题实体出发,通过平衡利用与探索来选择关系:
动机:选择PUCT而非随机采样或BFS,是因为其探索奖励能系统性地生成具有挑战性的负样本(频繁访问的关系容易混杂,但PUCT会探索语义合理但成功率低的关系),迫使RCVNet学习更精细的区分边界——这与共形预测需要高判别性分数的需求高度契合。
残差共形值网络(RCVNet):输入特征向量,整合局部语义相似度、路径相似度和关系先验。路径嵌入上下文向量经过FiLM层调制隐层激活,实现上下文感知的评分。RCVNet输出路径分数,通过成对排序损失训练:
查询-可交换共形预测(QE-CP)
动机:跳级校准无法绕过顺序依赖,但查询级独立性天然满足可交换性。因此将每个查询的整个推理过程封装为单个校准单元,定义结构化样本,并定义非符合分数为该查询中包含正确答案所需的最小路径分数:
TreeG检索:一种树状检索方法,利用LLM生成的关系提示和RCVNet分数指导扩展。提示增强分数:
动机:TreeG的确定性扩展避免了PUCT在推理时的随机采样,使得非符合分数在检索阶段是确定性的,从而满足CP对分数函数的固定性要求(split CP假设分数训练后固定)。同时,LLM提示提供了有噪声但有用的先验知识,与学习得到的分数互补——提示补偿了RCVNet可能未覆盖的罕见关系模式。
校准与预测:遵循标准split CP,计算校准分数的分位数:
论文提供覆盖保证定理(Theorem 4.1):对于任意测试查询,预测集以至少的概率包含一条正确推理路径,进而。证明分为六个步骤,核心逻辑是:查询级可交换性通过确定性函数传递至非符合分数,split CP的标准分位数论证保证覆盖,最后从分数覆盖推导路径覆盖和答案覆盖。
实验与结果
实验设置
数据集:WebQSP (2,543训练/283校准/1,628测试) 和CWQ (24,875训练/2,764校准/3,531测试)。为降低搜索开销,构建查询特定子图。校准集从训练集中随机抽取10%。
Baseline选择:包括三类——LLM共形基线CLM(基于logit的CP)、LoFreeCP(无需logit的CP变体,处理低频事件),以及KGQA共形基线UaG(阶段式CP,跳级校准)。论文未包括非CP方法(如RoG、PoG),因为实验目标是比较共形框架间的覆盖保证和集效率,这可以直接理解——非CP方法输出点预测而非集合,但作为效率参照本应提供;不过论文已经聚焦于共形场景,合理性在于问题定义本身是集合预测。
评估指标:ECR(经验覆盖率)、APSS(平均预测集大小)、Coverage Efficiency(ECR/APSS比值,衡量效率与覆盖的折中)。
实现细节:Qwen3-8B生成关系提示,all-MiniLM-L6-v2编码。PUCT滚轮32次/查询,探索系数。RCVNet隐层维度256,Adam学习率5×10⁻³,6周期。
主要结果
Table 2. 比较结果(WebQSP和CWQ)。最佳结果加粗。"—"表示未能满足覆盖保证(ECR < 1-α)。
| 数据集 | 方法 | ECR (%) ↑ (α=0.3/0.4/0.5/0.6/0.7/0.8) | APSS ↓ (相同α序列) |
|---|---|---|---|
| WebQSP | UaG | 72.3/60.4/51.8/41.8/37.4/25.6 | 98.81/32.52/14.29/8.23/5.58/1.67 |
| CLM | —/60.2/51.0/40.1/35.6/24.6 | —/46.69/14.37/5.74/2.78/1.82 | |
| LoFreeCP | —/60.0/50.1/41.0/36.7/24.1 | —/48.32/10.28/6.89/3.05/1.05 | |
| CPR Abl.1 | 76.0/65.5/57.3/53.4/49.8/43.2 | 22.05/14.84/10.10/8.26/3.80/2.16 | |
| CPR Abl.2 | 76.0/65.6/61.0/57.3/52.5/50.0 | 19.76/9.89/7.53/5.50/3.02/1.88 | |
| CPR | 76.8/67.3/61.4/58.3/55.1/50.8 | 17.77/10.10/7.14/5.45/3.01/1.62 | |
| CWQ | UaG | —/—/—/42.1/37.3/26.7 | —/—/—/120.20/99.16/27.96 |
| CLM | —/—/—/—/32.2/22.5 | —/—/—/—/10.48/5.33 | |
| LoFreeCP | —/—/—/—/32.0/25.6 | —/—/—/—/8.78/3.73 | |
| CPR Abl.1 | 72.2/65.5/57.8/50.0/42.2/27.6 | 33.43/27.84/20.50/14.41/10.96/4.61 | |
| CPR Abl.2 | 75.9/67.5/58.3/50.0/42.5/28.7 | 24.51/17.85/13.17/9.60/7.23/3.44 | |
| CPR | 76.6/68.1/58.8/50.2/42.8/29.9 | 23.98/15.28/11.40/8.35/6.08/3.39 |
关键观察:CPR在所有风险水平上均保持有效覆盖(ECR ≥ 1-α),而所有基线在较低α值时大面积失效(WebQSP上CLM和LoFreeCP在α=0.3失效;CWQ上UaG在α≤0.5失效,CLM和LoFreeCP在α≤0.6失效)。CPR的APSS相比UaG缩小显著:WebQSP α=0.3时从98.81降至17.77(降幅82%)。CWQ上的优势更突出:UaG在α=0.6时APSS高达120.20而CPR仅为8.35。
批判性评估:基线选择覆盖了三种共形思路,但UaG作为最相关的方法代表跳级校准,CLM和LoFreeCP代表LLM端共形。一个可能的缺失是将CP与非CP方法(如RoG+后处理校准)对比以显示覆盖保证的增量价值,但论文聚焦于共形框架间比较,问题定义已限定。实验结论有力支撑了核心claim:路径级校准比跳级校准更有效。但覆盖保证的理论条件(查询独立同分布)在数据划分中满足,真实部署中查询分布可能漂移,论文未讨论此场景。
消融实验
论文比较了全模型与两个消融变体:CPR Abl.1移除PUCT和RCVNet,仅靠TreeG检索+语义分数;CPR Abl.2保留RCVNet但用随机负样本替代PUCT收集的轨迹。WebQSP α=0.5时,从Abl.1(57.3% ECR)到Abl.2(61.0%)再到全模型(61.4%)的逐步提升表明三个组件互补:TreeG提供基础可达性,RCVNet增强判别,PUCT提供高质量训练轨迹进一步增强判别。这验证了PUCT的离线训练价值——它虽在推理时被替换为TreeG,但训练的RCVNet仍保留了高质量信号。
覆盖效率分析
Coverage Efficiency(ECR/APSS)综合评估可靠性与紧凑性。WebQSP α=0.5时CPR达0.086,较UaG(0.036)提升140%,较CLM(0.035)和LoFreeCP(0.049)也有显著优势。CWQ α=0.6时差距进一步拉大:CPR达0.060,UaG仅为0.004。注意到UaG在CWQ上虽然APSS极大(意味着几乎整图),ECR却仍不满足覆盖——这直接暴露了跳级校准的理论缺陷。
搜索预算分析
论文在WebQSP上调整branch-out size B和active-set size A,固定α=0.5。结果显示从(4,8)到(64,64),ECR从0.582升至0.629但APSS从3.09升至9.02,边际收益递减。有趣的是(16,8)的ECR低于(8,8)——这可能意味着过多分支但全局容量不足时,TreeG会引入噪声路径反而干扰top-A保留。论文据此选择(B,A)=(32,32)。
批判性评估:验证了TreeG的敏感性,但消融未单独评估LLM提示的作用。提示是TreeG的核心组件之一(通过式8中的提示奖励项),其质量和确定性影响检索结果。论文使用Qwen3-8B零温度生成以确保确定性——这保证了非符合分数的可交换性,但提示本身的准确性对覆盖效率有何影响?实验未包括无提示的消融。同时,子图构建策略(从全量Freebase到查询特定子图)的偏移风险——如果子图本身遗漏关键路径,即使CP保证也无法找回。论文对此有所觉悟(在Impact Statement中提及依赖底层知识图谱质量),但未定量分析子图缩小带来的覆盖率上限损失。
优势与局限性
优势:CPR首次在KGQA中实现了路径级共形校准,理论上恢复了可交换性,经验上显著优于跳级基线。通过PUCT+RCVNet的组合学习判别性分数,有效缩小了预测集。计算代价分配合理:离线训练(PUCT滚轮32次/查询)转化为在线推理的轻量级TreeG扩展,具有实际部署价值。覆盖效率指标清晰揭示了紧凑性与可靠性的权衡。
局限性:第一,覆盖保证是统计性质的,仅保证在多次重复中至少1-α比例包含正确路径,不保证单个查询一定正确。这在Impact Statement中已明示,值得注意。第二,子图构建步骤未在理论框架内讨论——如果子图遗漏答案,则覆盖保证的前提条件(包含正确答案)不一定成立。实践中可能需额外机制确保子图完整。第三,RCVNet的训练依赖PUCT生成的路径对,而PUCT本身使用Beta先验和语义先验,这些先验的可靠性在Cold-start场景下(关系未充分探索)可能有限。第四,TreeG使用LLM提示且需要零温度确保确定性,若下游LLM服务不稳定或API支持变温,确定性可能被破坏。第五,可复现性评估:代码未公开(论文未提及仓库),但实验设置描述详尽(模型、超参、提示模板均给出),理论上可复现。缺乏跨随机种子的稳定性报告——校准集划分是随机的,但未报告多次运行的标准差。
未来方向与开放问题
论文自身提出几个未解决问题:第一,跳级校准问题正式化为顺序依赖链,但路径级校准以丢失路径内细粒度不确定性为代价——能否设计混合粒度方法在保持可交换性的同时利用跳级信息?第二,PUCT轨迹收集依赖地面真相答案存在时的成功率统计,面对部分已知答案的训练场景时如何拓展?第三,TreeG中的LLM提示调用需工程成本,能否设计完全自监督的提示生成或不依赖提示的检索仍保持效率?值得进一步思考的方向:覆盖保证对知识图谱补全或演化后的再校准需求;跨域迁移时查询分布漂移下的鲁棒性;以及将路径级校准扩展至概率知识图谱领域(如UnKGCP的实体不确定性建模)。
组会预判问答
Q1: 跳级校准只要阈值设得严一些,理论上是否可能满足覆盖?
论文通过形式化定义明确指出顺序依赖使得跳级校准跨样本纠缠,并非仅阈值问题:即使阈值严格,第k步预测集的大小仍会影响第k+1步的可达实体集合,而该集合本身依赖于早前校准样本。论文举例"《盗梦空间》导演"说明:若跳1排除了关键实体,后续永远无法到达正确答案。因此阈值调节无法从结构上修复可交换性的违反。
Q2: RCVNet为什么使用残差连接并初始化为零?论文未消融此设计,是否必要?
论文在附录C中说明输出层初始为零以确保初始残差,使模型从语义基线开始学习。可以理解为,这避免了初始阶段输出随机方向导致的训练不稳定。但论文未设计消融实验量化此设计对最终性能的影响——一种可能的解读是,既然语义基线已经提供合理排序(正确路径的语义相似度通常高于错误路径),残差设计允许网络"微调"而非"推翻"基线,这应该降低了训练难度。
Q3: TreeG检索中的LLM提示生成是确定性的吗?如果LLM返回的不确定,是否会破坏QECP的可交换性?
论文明确使用零温度(温度=0)解码并关闭思考模式,确保同一查询重复调用返回相同提示。非符合分数通过TreeG和RCVNet计算,两者都是确定性函数。查询可交换性建立在是的确定性函数之上。如果未来改用非确定性LLM,则在同一查询下的分布不再固定,可交换性需要重新论证(可能需引入随机性在平均意义下保持)。这一考虑体现了论文当前设计的理论严谨选择。
Q4: 覆盖效率指标中,为什么CWQ上UaG的ECR/APSS极低,而CPR仍有改进空间?
CWQ问题更长更复杂,跳级校准的顺序依赖更加显著——多跳使累积依赖更强,UaG几乎只能以极保守的阈值勉强满足部分覆盖,导致APSS高达120甚至更大(几乎返回整个子图)。CPR将校准提升至路径级,规避了跳级依赖,但CWQ上仍有29.9%的查询未覆盖(α=0.8时ECR 29.9%,刚好满足1-α=20%保证)。这可能意味着在查询分布更复杂时,TreeG检索无法保证所有查询包含正确答案路径——这指向子图构建覆盖率的底层问题。
本报告由立理AI生成,仅供参考,请以原文为准。