结构变体优于LoRA:RLVR下PEFT方法的系统评估
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Evaluating Parameter Efficient Methods for RLVR |
| 作者 | Qingyu Yin, Yulun Wu, Zhennan Shen, Sunbowen Li, Zhilin Wang, Yanshu Li, Chak Tou Leong, Jiale Kang, Jinjin Gu |
| 机构 | 浙江大学、香港科技大学、华盛顿大学圣路易斯、中国科学技术大学、布朗大学、香港理工大学、INSAIT |
| 论文地址 | https://arxiv.org/abs/2512.23165 |
| 代码地址 | https://github.com/PeRL |
| 发表时间 | 2025年12月 |
一句话概要
论文首次系统评估了12种以上参数高效微调(PEFT)方法在基于可验证奖励的强化学习(RLVR)范式下的表现,
基于DeepSeek-R1-Distill系列模型在数学推理基准上进行了大规模实验。
核心发现挑战了默认使用标准LoRA的做法:结构变体(DoRA、AdaLoRA、MiSS)一致优于LoRA;
SVD初始化策略(PiSSA、MiLoRA)因与RL优化动态的频谱错配而遭遇训练崩溃;
极端的参数压缩(VeRA、Rank-1)则形成了表达性瓶颈。
论文揭示了频谱塌缩现象并提供了机制解释。
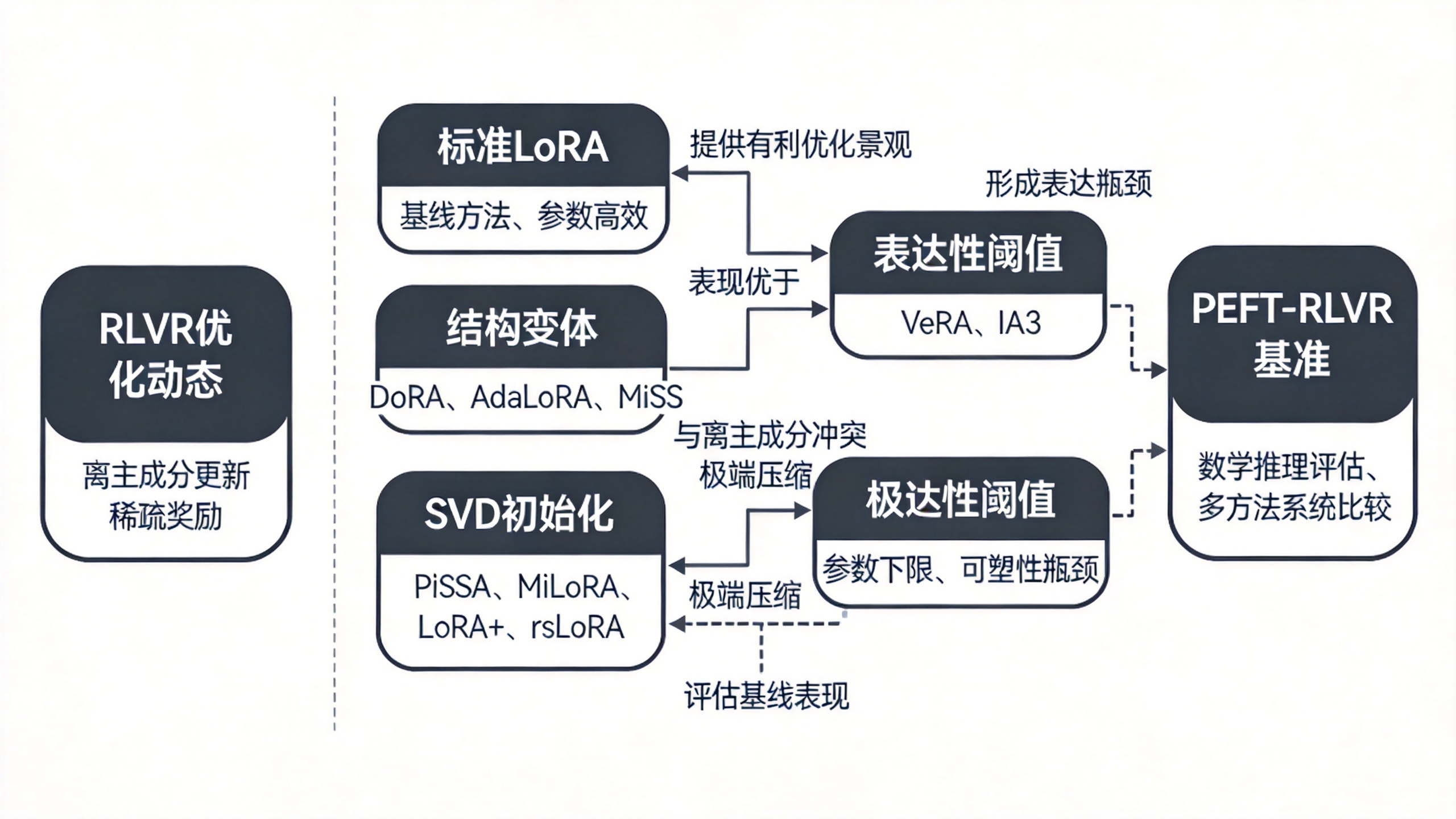
背景与研究动机
大型语言模型在复杂推理任务中已展现出卓越能力,尤其是在数学和科学领域。近年来,基于可验证奖励的强化学习(RLVR)成为进一步增强推理能力的主导范式。与依赖人类偏好的传统RLHF不同,RLVR利用确定性验证器(如数学答案匹配或代码执行结果)提供稀疏但准确的二进制奖励信号,能够激发模型的自我纠正和迭代改进等复杂行为。
然而,强化学习的训练过程本身以复杂和资源密集著称。一个关键低效来源在于监督信号的性质差异:有监督微调(SFT)受益于密集的知识传递(教师强制),而RLVR依赖的稀疏监督信号通常表现为1比特奖励。论文指出,这种稀疏性导致更新被局限在小的子网络或稀疏参数上,意味着全参数RL训练中存在显著的参数冗余。因此,通过参数高效方法优化RL具有广阔空间。尽管LoRA已被证明能在RL中取得与全参数训练竞争的性能,但问题在于:当存在大量LoRA变体和其他PEFT方法时,标准LoRA架构是否真的是RL独特优化动态下的最优选择?
由此引出论文的核心研究问题:哪种参数高效方法最适合强化学习?
现有方法的瓶颈
论文指出,当前领域存在三个关键局限:
第一,LoRA的默认采用缺乏验证。尽管LoRA(低秩适应)已成为参数高效微调的事实标准,且大量变体(如DoRA、AdaLoRA、PiSSA等)涌现,但这些技术在RL场景中的应用几乎完全局限于标准LoRA。这意味着领域内并不清楚面向SFT设计的方法在RL的稀疏奖励、非密集梯度信号下是否仍然有效。
第二,SVD初始化方法的理论基础存在缺口。近年来,基于奇异值分解的初始化策略(如PiSSA、MiLoRA)在SFT中展现出加速收敛的优势。这些方法的核心思路是利用预训练权重的谱结构来初始化低秩适配器。然而,这些方法在RL中的表现——特别是它们是否与RL的特殊优化动态兼容——几乎没有被系统研究过。
第三,参数压缩程度与推理能力的阈值关系不明确。虽然最近的发现表明RLVR与低秩更新兼容,但在参数效率上是否存在一个不可逾越的下限,即多少参数是维持推理能力所必需的,这一关键问题尚未有明确答案。
论文的实验设计正是围绕这三大瓶颈展开,试图填补从多样化PEFT方法到RLVR特定优化动态之间的系统性空白。
核心洞察与贡献
论文的核心洞察来源于对RLVR优化动态与PEFT方法设计范式之间对齐程度的深入理解。作者指出,RLVR的更新具有“离主成分”特性——与SFT倾向于更新高幅值的主成分权重不同,RLVR的更新一致地定位到低曲率、非主成分的子空间。基于这一理解,论文对三类PEFT方法做出了区分性分析。
论文的主要贡献归纳如下:
-
首个系统的PEFT-RLVR基准:建立了一个大规模基准评估超过12种参数高效方法,证明标准LoRA对RLVR而言并非最优选择。
-
结构变体的优越性:通过实验证明DoRA、AdaLoRA、MiSS等结构变体一致优于标准LoRA,且DoRA甚至超过全参数微调的性能。
-
SVD初始化失效的机制解释:揭示基于SVD的初始化策略(PiSSA、MiLoRA)的关键失效模式,通过谱分析提供机制解释:这些方法强制在主成分上更新,与RLVR的内在离主成分倾向产生结构性错配。
-
表达性下限的识别:确定参数效率的一个清晰性能边界,证明极端参数压缩方法(如VeRA、Rank-1适配器)会创建信息瓶颈,严重限制推理所需的可塑性。
-
可扩展性与鲁棒性验证:通过将实验扩展到7B参数规模并进行广泛的消融研究(批大小、学习率、秩),验证了发现的泛化能力。
方法详解
RLVR框架:Group Relative Policy Optimization
论文采用Group Relative Policy Optimization(GRPO)作为基础RL框架。对于给定提示q,GRPO采样一组G个响应{o₁,…,o_G},并优化如下目标函数:
其中优势估计 (\hat{A}_i = (R_i - \text{mean}({R_j})) / \text{std}({R_j})) 通过组内统计量标准化,无需独立的批评模型。论文采用DAPO(一种引入Clip-Higher策略和动态采样的GRPO改进版本)作为标准训练算法。
PEFT方法分类
论文将所评估的12种以上PEFT方法分为五个类别:
基线方法:包括全参数微调和标准LoRA。LoRA的前向传播定义为:
其中A初始化为随机高斯噪声,B初始化为零,确保训练开始时(\Delta W = 0)。
结构变体:这类方法从根本上改变了标准低秩分解的架构形式。包括DoRA(解耦幅度和方向)、AdaLoRA(SVD式自适应秩结构)和MiSS(分片子网络选择)。论文假设这些结构的优势来源于它们引入了更强的归纳偏置,更适应RLVR的优化动态。
初始化策略:保持标准LoRA架构但干预初始化或优化动态。包括基于SVD的PiSSA(使用主成分初始化)、MiLoRA(使用次要成分初始化),以及基于学习率调节的LoRA+(差异化学习率,(\eta_B \gg \eta_A))和rsLoRA(稳定秩缩放因子)。
效率导向变体:包括LoRA-FA(冻结A矩阵)和VeRA(冻结随机投影矩阵,仅训练缩放向量)。
其他PEFT机制:包括IA3(激活向量元素级缩放)和LayerNorm微调。
实验设置
基础模型:采用DeepSeek-R1-Distill-Qwen-1.5B和7B两个规模的推理模型。选择标准包括:已完成SFT冷启动以确保足够的推理能力;涵盖不同参数量级以分离规模效应。
训练数据:使用open-r1/DAPO-Math-17k-Processed数据集,包含约17.4k高质量数学查询。强制结构化推理格式:标签内推理轨迹,\boxed{}封装最终答案。
奖励机制:基于结果的严格二进制奖励。使用latex2sympy和math_verify进行答案匹配验证。
超参数:对1.5B模型,每设备批大小4、全局批大小128,训练1024步;对7B模型,每设备批大小1、全局批大小32,训练8192步。学习率固定为1e-5(常数),LoRA秩32,dropout 0.05,alpha 64。
评估:使用MATH-500、AIME24/25、AMC、Minerva和HMMT基准。采用Avg@k和Pass@k指标(AIME/AMC/HMMT使用@32,MATH500/Minerva使用@4),温度0.6,top-p 0.95。
实验与结果
主要结果
论文的核心实验结果清晰地支持三大发现。
发现一:标准LoRA对RLVR而言并非最优。 结构变体——解耦学习动态的DoRA、分片参数的MiSS和自适应参数分配的AdaLoRA——代表当前RLVR中超越LoRA的最优参数高效选择。
实验结果显示,标准LoRA(平均准确率42.5%)作为基线尚可,但始终落后于全参数微调(44.9%),表明其刚性低秩约束在面对RL所需的复杂策略转变时存在局限。相比之下,结构变体有效弥补甚至超越了这一差距。DoRA以46.6%的平均准确率打破天花板,在多个基准(如AIME和AMC)上超越全参数基线。AdaLoRA(44.2%)和MiSS(43.4%)也一致优于标准LoRA。
值得注意的是,论文所提供的解释性分析仍有待深化。作者将结构变体的优势归因于“缓解了标准LoRA固有优化刚性”,并假设这源于这些变体的架构归纳偏置与RLVR独特优化动态之间的基本对齐。然而,论文并未提供直接的数学证据或表征方法来证实这种“对齐”存在的具体形式,因此这一结论更多停留在假设层面。
发现二:RLVR要求最低表达性阈值。 虽然适度参数缩减(如LoRA-FA)有效,但极端参数缩减方法(如VeRA、IA3)依赖纯向量更新,缺乏重新定向推理回路所需的可塑性。
论文观察到,适度压缩——例如LoRA-FA(冻结投影矩阵A,仅训练B)维持了接近标准LoRA的性能,表明RLVR信号虽然稀疏,但足以在半冻结的低秩子空间中驱动更新。然而,VeRA(冻结两个低秩矩阵,仅学习缩放向量)降至40.7%准确率,IA3更是急剧下降至22.3%。这表明RLVR对可训练适配器容量有最低要求,将其缩减为纯缩放向量会形成瓶颈,阻碍模型学习复杂推理行为。
发现三:现有SVD初始化策略不适用于RLVR。
PiSSA遭遇了灾难性崩溃(0.2%准确率),而MiLoRA(18.0%)也显著落后于标准基线。论文提供了机制性解释:PiSSA失效源于明确将更新限制在主成分子空间((U[:r], V[:r])),这与RLVR的离主成分特性直接冲突。
更关键的是MiLoRA的失效分析。理论上,MiLoRA使用次要成分((U[r:], V[r:]))初始化适配器,应能与RLVR的离主成分特性对齐。但实验结果首先表现出奖励增加,随后无法收敛。论文通过谱分析揭示了机制:尽管初始化为离主成分子空间,MiLoRA最终的更新在主成分处出现尖锐峰值((k \approx 0)),行为几乎与PiSSA相同。
论文将更新动态形式化为:
这一形式化分析具有高价值。初始适配器状态有效坍缩为零,因为没有显著初始偏置(|\Delta W_0|_F)的情况下,优化轨迹由梯度(\nabla L)的谱性质决定。由于梯度与最大方差方向(主成分)对齐,更新重新投射到主成分子空间,导致模型从离主成分退化回主成分更新,表现为谱尖峰。
值得注意的是,这一分析存在一个可能的盲点:如果初始幅值很小是问题根源,那么是否可以通过对MiLoRA的初始值进行缩放(即在等式右侧引入一个非零的(|\Delta W_0|_F)因子)来缓解?论文未对此进行消融验证。
消融研究
论文进行了四维消融:批大小、RLVR算法、学习率和LoRA秩。
批大小:减小批大小至32得到略高平均准确率42.5%。但在AIME 2024基准上大批更好。这支持了SFT中的小批启发式在RLVR中一定程度适用的看法,但优势较小。
RLVR算法:在GRPO、DAPO和Dr. GRPO三种算法下,PEFT方法的性能高度一致。这表明PEFT有效性受RLVR基本动态驱动,而非特定损失函数细节。
学习率:证实学习率幅度是RLVR稳定性的决定性因素,最优性能在特定缩放法则下实现。
LoRA秩:秩1的配置持续低于更高秩配置(秩16、32效果更佳)。论文建议避免极端秩缩减,维持适度秩以确保充分表达性。
批判性评估:消融实验的主要局限在于,论文仅对LoRA方法进行了消融,未验证其他方法(如DoRA、VeRA)在不同批大小、秩和学习率下的行为是否一致模式。这意味着关于“结构变体优势是否敏感于超参数选择”的结论仍然较为脆弱。此外,学习率消融仅报告了LoRA的结果(Table 5中注明为rsLoRA?),关键优化器选择(如Adam vs. SGD)未纳入比较。
规模扩展
在7B模型上,相对性能层次保持稳定。DoRA(55.0%)和LoRA+(55.5%)一致优于标准LoRA(54.8%),表明结构变体优势并非小模型规模的人为产物,而是RLVR优化景观的内在特性。
优势与局限性
优势
论文的最大优势在于系统性。首次在大规模、多设置、多方法条件下对PEFT在RLVR中的表现进行统一比较,涵盖12种以上方法、两个模型尺度和六个推理基准。实验设计考虑了统一超参数、受控条件,增强了结论的可信度。
可复现性评估:论文在多个方面具备良好的可复现性。代码已以PeRL仓库开源,使用HuggingFace和Wandb进行实验追踪,提供了详细的超参数配置。TRL框架和DeepSeek模型均为开源可用资源。
关键发现的稳健性:三大核心发现在多个维度得到交叉验证——规模扩展验证了泛化能力,消融验证了对超参数的鲁棒性(至少在LoRA上),算法不变性的验证表明结论可能适用于更广泛的RLVR家族。
局限性
搜索空间有限。论文虽然评估了12种方法,但PEFT设计空间远更大。例如,未考虑混合方法(如结构变体+初始化改进)的组合,也未探索不同秩、不同目标模块组合的非平凡交互。
对全参数基线的比较有偏差。论文发现DoRA(1.55%参数)超越了全参数微调(100%参数),但这可能受到训练步数不足或未充分优化全参数超参数的影响。论文的训练设置(统一学习率、固定步数)可能对全参数方法不利,因为全参数方法通常需要不同的学习率调度或更长时间收敛。
机制解释尚欠完备。论文提供的谱分析对理解SVD初始化的失效具有启发价值,但对于“为什么结构变体成功”的解释仍然停留在归纳偏置对齐的抽象层面,缺乏量化验证。例如,能否直接测量DoRA适配器的有效秩演化或谱分布,以证明其与RLVR的离主成分特性存在更好对齐?
工程设置的限制。论文使用TRL框架,作者自身也承认其在大规模分布式训练中的局限性。更大的模型(如70B或更大)或更长的训练周期下的行为尚未验证。此外,论文仅讨论了单一类型的奖励(数学验证),对代码执行、多步推理等其他RLVR任务场景的适用性未知。
未来方向与开放问题
论文在“未来工作”部分提出了三个方向,但每个方向都存在值得追问的开放问题。
基础架构升级。作者指出当前TRL框架的限制,计划迁移到VeRL等高性能框架。这意味着当前的实验结论是否受到框架效率瓶颈的影响是一个悬而未决的问题。考虑到RL训练对采样效率敏感,不同的rollout机制或优势估计实现方式是否会影响PEFT方法的相对排序,值得后续验证。
适配器动态的机械可解释性。这是论文自身承认的最关键缺口。尽管观察到结构变体有效而SVD初始化失效,但“为什么特定结构偏置对稀疏、离主成分的RL优化至关重要”的精确数学理由尚待阐明。潜在的方向包括:跟踪适配器更新过程中奇异值分布的全动态过程;建立RLVR更新方向与适配器参数空间曲率之间的关系;形式化地证明结构(如幅度-方向解耦)如何为RL的稀疏奖励提供更有利的优化景观。
更广泛的前沿与部署稳定性。论文计划将评估扩展到多模态环境、多轮交互和异步RL设置。一个值得关注的开放问题是:在异步RL中,不同PEFT方法的数值稳定性(特别是权重合并时的一致性)是否存在差异?这在当前实验中被忽略,但对实际部署至关重要。此外,论文未讨论训练与推理阶段之间的潜在不一致性问题——适配器的动态行为(如DoRA的方向归一化)在推理时是否需要特殊处理。
组会预判问答
Q1: DoRA能够超越全参数微调,是否说明全参数训练在某些条件下不如PEFT?这是否可以被理解为参数冗余导致的过拟合?
论文的实验数据支持DoRA(46.6%)超越Full(44.9%)这一可量化的客观结果。论文在结论中谨慎地将这一现象归因于结构变体的架构优势,而非直接称全参数训练存在过拟合。一种可能的解读是:论文的统一实验设置(如固定学习率、相同步数)可能对全参数微调不利——全参数方法通常需要更精细的学习率调度或更长的训练周期才能充分收敛。此外,论文中全参数方法使用ZeRO-2优化器状态卸载,也可能引入了额外的优化不稳定性。若在同一条件下比较全参数方法在不同优化器设置下的性能,会增强结论的说服力。
Q2: 论文提出MiLoRA失效是因为初始化幅值接近零,导致梯度重新主宰更新方向。这个解释是否意味着通过放大MiLoRA的初始范数可以解决该问题?
论文提出MiLoRA初始适配器状态有效坍缩为零,同时梯度天然与主成分对齐,导致更新方向被梯度主导。这一认识暗示了潜在的补救策略:如果在初始化时施加一个非零的(|\Delta W_0|F)约束,可能有概率维持离主成分更新路径。但论文指出次要成分对应奇异值(\sigma{tail} \rightarrow 0),这意味着任何明显的初始偏置可能需要额外缩放。论文未进行此类实验,因此这是一个值得后续验证的假设方向。
Q3: 论文的消融实验只对LoRA进行了,结构变体的结论是否对超参数变化足够鲁棒?
这是一个实质性的局限。论文的消融(批大小、学习率、秩、RL算法)仅以标准LoRA为对象进行变化。虽然论文在结论中声称结构变体优于LoRA的发现是鲁棒的,但这一声明并未经过严格的超参数敏感性验证。例如,DoRA在不同学习率下是否仍一致优于LoRA?AdaLoRA的秩分配机制是否在更小的秩约束下依然有效?论文本身提供了DoRA和LoRA+在7B尺度上的互补验证,这在一定程度上缓解了该担忧,但系统的超参数消融仍然是缺失的一环。
Q4: 论文中VeRA(0.0029%参数,40.7%准确率)仅略低于全参数基线(44.9%),是否意味着极度参数效率仍有可能通过其他方式实现?
从论文的数据看,VeRA的参数量仅为LoRA的约1/500,但准确率仅下降约1.8个百分点(42.5%→40.7%)。在成本极度受限的场景下,VeRA可能具备实用价值。但论文也将LN Tuning(0.0035%参数,41.8%)列为同类压缩方法——LN Tuning甚至略优于VeRA,说明参数量与性能之间并非简单的单调关系。论文在结论中的核心观点是极端缩减“创造结构性瓶颈”,但此处的数据也提示存在超出总参数量之外的设计因子,例如参数的分布位置(是影响所有层还是局限于特定模块)可能比纯粹的量化缩减更重要。
本报告由立理AI生成,仅供参考,请以原文为准。