测度论视角下的扩散、分数与流匹配统一框架
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | A Unified Measure-Theoretic View of Diffusion, Score-Based, and Flow Matching Generative Models |
| 作者 | Aditya Ranganath, Mukesh Singhal |
| 机构 | Lawrence Livermore National Laboratory, University of California Merced |
| 论文地址 | https://arxiv.org/abs/2605.06829 |
| 发表时间 | 2026年5月7日 |
一句话概要
论文提出一个基于测度论的概率传输统一框架,将连续时间扩散模型、基于分数的生成模型与流匹配归入同一条学习变分向量场的叙事主线。核心洞察在于:所有方法均可由路径选择(ρt)、学习对象(分数场 vs 速度场)和采样动力学(SDE vs ODE) 三个设计轴唯一描述;逆向时间SDE与概率流ODE共享相同单时边际分布,且DDPM、去噪分数匹配与连续时间分数SDE目标函数在加权意义下彼此等价。该框架为理解不同方法的误差来源、路径设计与采样稳定性提供了统一的数学语言。
背景与研究动机
生成建模的核心目标是从简单参考分布(如标准高斯)向复杂数据分布进行概率传输。过去十年,变分自编码器、生成对抗网络和标准化流分别从显式似然、隐式生成和可逆映射三条路径逼近这一目标。扩散概率模型(DDPM)通过逆向离散时间马尔可夫链生成样本,基于分数的生成模型利用随机微分方程(SDE)对逆向时间采样进行形式化,而流匹配则直接学习确定性传输的速度场。这三条路线在实践中各有侧重——扩散模型擅长高保真合成,分数模型提供了灵活的采样框架,流匹配则可扩展至离散状态空间与非欧几何结构——但它们在数学结构上是否存在更深层的统一性,尚缺乏一个同时涵盖路径、学习对象和采样动力学的系统化理论。
作者认为,当前文献存在三个突出问题:第一,这些方法的边界已日益模糊——分数SDE显式导出确定性的概率流ODE,流匹配又将扩散路径作为特例处理,但缺乏一个统一符号系统将它们等价关系讲清楚;第二,表述碎片化——扩散模型常通过离散时间马尔可夫链引入,分数模型依赖SDE时间反转,流匹配则从向量场回归出发,不同推导风格掩盖了核心设计选择的本质相似性;第三,采样稳定性与计算代价高度依赖于路径选择、离散化方案和求解器,这些数值因素在统一框架下才能被系统分析。这一问题在逆问题、条件生成等下游任务中尤为突出——同一个学习模型在不同离散化行为下可能表现出截然不同的重构保真度。
现有方法的瓶颈
已有综述和教程要么侧重扩散模型本身,要么聚焦流匹配或高效采样,缺乏一个统一的概率传输视角。具体而言,现有方法面临以下局限:
- 路径定义不统一。扩散模型将路径(ρt)隐式定义为前向噪声SDE的边际分布,参数化受限于特定噪声时间表(如VP/VE SDE);流匹配则将路径视为显式建模选择(通过耦合与插值规则),但两者之间缺乏一个可互相比较的数学语言。不同路径设计对训练和采样行为的影响无法在单一框架内分析。
- 学习对象与采样动力学的关系未澄清。分数模型学习分数场sθ,然后通过概率流ODE诱导出一个速度场;流匹配直接学习速度场vθ。在这两种参数化下,前向SDE、逆向SDE、概率流ODE和确定性传输之间的边际等价性与路径测度差异被分散表述,容易造成“SDE采样与ODE采样是否等价”等基础问题上的混淆。
- 训练目标的等价性被低估。DDPM通常使用噪声预测损失,基于分数的模型使用去噪分数匹配,连续时间SDE框架使用加权时间积分形式。这些目标常被视为不同的统计估计问题,但事实上它们都归结为加权分数回归——区别仅在于参数化方式和隐式施加的时间加权。
- 误差分解缺乏系统框架。生成质量下降通常混合了近似误差、估计误差、数值离散误差和路径失配,而现有工作往往孤立处理其中一个方面,缺少将这些误差在统一场-求解器抽象下进行联合分析的视角。
核心洞察与贡献
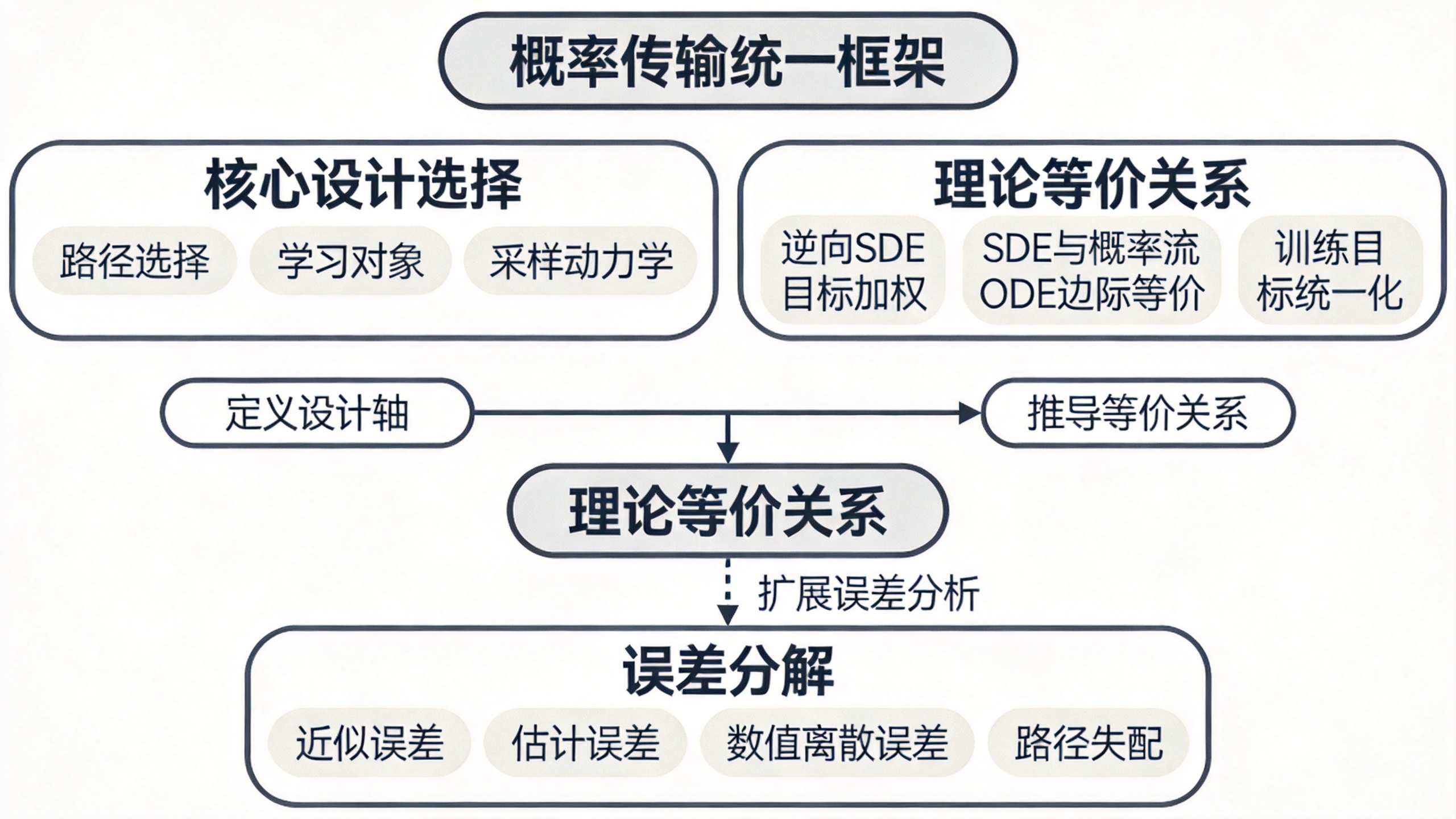
论文的关键洞察在于:扩散、分数与流匹配应被统一理解为概率传输问题——一个通过SDE或ODE演化边际分布族(μt)t∈[0,1]的过程,其核心设计选择可分解为四个独立轴:路径类型(ρt)、学习对象(分数 vs 速度)、采样动力学(SDE vs ODE)以及目标加权/数值误差。一旦采用这一视角,许多表面差异本质上只是参数化和耦合选择的差异,而非范式对立。
具体贡献如下:
- 统一传输视角:论文将所有连续时间生成模型纳入一个公共框架,使用SDE/ODE动力学及其关联的Fokker–Planck/连续性方程来描述概率演变。这一做法使得扩散、分数与流匹配的方法论差异被归结为路径、学习对象和采样动力学三个有限选择空间内的不同组合。
- 采样动力学的等价映射:严格形式化逆向时间SDE与概率流ODE之间的边际等价性(Proposition 3),指出两者共享相同单时边际但不共享路径测度。这一理解为确定性采样是否可作为随机采样的替代提供了理论边界。
- 训练目标的统一化:通过Proposition 2表明,DDPM噪声预测损失、去噪分数匹配和连续时间分数SDE目标函数均可写为加权时间积分形式的分数回归,区别仅在参数化权重和隐式时间安排。这一等价性揭示了不同“损失”背后相同的统计估计对象。
- 理论-实践桥梁:从误差源的角度(近似、估计、数值、路径失配)对生成质量退化进行系统分解,并基于此指出路径设计、联合学习-求解器分析、鲁棒泛化等开放问题。这一桥梁将理论与工程关切(如快速采样、逆问题稳定)衔接起来。
值得注意的是,论文还通过明确区分“边际等价”与“路径测度等价”来预防概念混淆,并利用测度论语言(推前测度、路径测度)在无密度假设下定义传输概念,这使得后续扩展至离散状态空间、函数空间或Wasserstein空间成为可能。
方法详解——统一概率传输框架
论文的核心框架围绕四个设计选择展开,其数学基础建立在SDE/ODE及其对应的PDE关系上。
路径ρt。 时间t∈[0,1],t=0对应数据分布μ0,t=1对应参考分布μ1。扩散/分数方法将路径定义为前向SDE的边际分布族;流匹配则通过一个耦合π(x0,x1)和一个显式插值规则(如仿射插值xt = a(t)x0 + b(t)x1)直接指定中间状态xt的分布。两种方式都产生一个概率路径(μt),但扩散路径由固定噪声过程约束,而流匹配路径是可自由设计的。
学习对象:分数vs速度。 分数场定义为st(x) = ∇x log ρt(x),需要密度ρt存在;速度场vt(x)直接定义在欧氏空间上,通过连续性方程∂tρt + ∇·(ρtvt)=0与路径耦合。论文严格论证了两者之间的桥梁:对于给定的前向SDE,其概率流ODE的速度为vPF(x,t) = f(x,t) - ½g(t)² st(x)。因此分数场可以诱导出速度场,但反之不一定成立——流匹配学习速度场时不需要中间密度可微。
采样动力学:SDE vs ODE。 逆向时间SDE(Proposition 1)是随机采样,其漂移项包含分数场:dXt = [f(Xt,t) - g(t)²∇log ρt(Xt)]dt + g(t)dW̄t。概率流ODE(Proposition 3)是确定性的,速度由分数场诱导。两者共享相同单时边际分布,但路径测度不同。这一区别在数值分析上至关重要:SDE采样的随机性可辅助探索但引入方差;ODE采样确定性但可能因刚度导致离散化误差。
目标加权与数值误差。 训练目标(Proposition 2)可统一为时间积分的加权Fisher散度:∫₀¹ λ(t) E_{x~ρt} ‖sθ(x,t) - st(x)‖² dt。不同算法差异在λ(t)的选择和参数化(噪声预测、x0预测、分数预测)上。数值误差包括SDE/ODE离散化偏差、时间表/路径失配等。
论文进一步将这一框架扩展至Schrödinger桥和熵最优传输,通过路径测度的KL最小化将扩散模型理解为受端点约束的最优随机控制问题。附录提供了逆向时间扩散(已故代数推导)、概率流ODE的PDE来源、目标等价性(去噪分数匹配、DDPM、连续时间目标)以及流匹配条件期望最优速度的L²投影证明。
文献分析与评估
论文的分类框架以“路径-场-采样器”三个轴为核心,将扩散、分数、概率流ODE、流匹配和整流流置于同一张比较表中。这一分类的合理性在于:它抓住了方法之间最本质的差异——即路径如何定义(SDE边际 vs 显式耦合)、学习对象是什么(分数vs速度)以及采样是随机还是确定。相比之下,传统按照“离散链 vs 连续过程”或“隐式 vs 显式似然”的分类更易遮蔽设计选择间的潜在等价关系。
文献覆盖方面,论文兼顾了经典工作(DDPM、score-SDE、CNF、FFJORD)与前沿扩展(冷扩散、随机插值器、贝叶斯流网络、一致性模型、离散扩散),并涵盖离散状态空间(D3PM、模拟比特、离散流匹配)、函数空间流匹配、Wasserstein流匹配等新兴方向。这种覆盖广度在一个统一综述中是必要的——它验证了三个设计轴确实能够容纳看似异质的变体。
批判性观点方面,论文指出了当前评估指标的不足(如FID可能对扩散模型与流匹配模型表现不对称),但引用了具体文献来支撑这一判断。在误差分解上,论文提出了概念性框架但承认真正严格的联合界限仍缺失,这种坦诚有助于避免过度承诺。
一个值得注意的局限是:论文对“路径-场-采样器”框架的有效性论证主要依赖于形式化等价推导(Propositions 1–4),而非系统的实验对比。这使得框架的实用指导价值受限于读者能否将自身方法映射到这三个轴上。论文作者也承认仍有诸多开放问题(如高维保证、泛化性),表明该框架距离成熟的工程指南还有距离。
优势与局限性
优势:第一,论文提供的统一符号体系(Table 1)使不同工作可在一套标准记号下进行比较,降低了跨文献阅读的理解成本。第二,Propositions 1–4构成了一个严谨的等价链,明确了逆向SDE、概率流ODE、分数匹配目标和流匹配目标之间的理论关系。这些等价的成立条件(密度存在性、正则性假设)被明确标注,避免了过度推广。第三,误差分解为一个概念工具,有助于研究者定位其方法中的主要性能瓶颈——是近似能力不足、有限样本估计偏差,还是数值离散化主导了退化。第四,文献覆盖面广且组织了清晰的阅读引导(应用ML轨道、ML理论轨道、数学/统计轨道),适配不同需求的研究者。
局限性:第一,论文未提供任何原始实验,所有比较和结论基于现有文献的理论推导。这意味着框架的有效性主要依赖其内部一致性,而非与baseline的实证对比。第二,可复现性有限——论文未开源代码(作为综述这是合理的),但部分形式化推导(如目标等价性的完整证明)被归入附录,主文仅给出非正式陈述,阅读友好性和严格性之间存在张力。第三,论文指出“路径-场-采样器”是核心设计轴,但对如何系统地为给定任务选择最佳组合缺乏量化准则。定性指南如“若需要随机多样性可选SDE采样”有其合理性,但在高维实际场景中可能不够具体。第四,路径测度与边际分布的区别虽然理论重要,但在实际算法中很难直接测量或控制,这一概念深度与工程距离之间存在一定落差。
未来方向与开放问题
论文在结论部分列出了七大开放问题,这些问题相互关联又各有侧重:
- 路径与时间表的原理性设计:如何在不同计算预算下选择刚度小、集中模型容量、对逆问题鲁棒的路径?论文指出EDM、整流流、临界阻尼Langevin扩散等工作暗示了路径自由度的丰富性,但尚缺统一理论。
- 联合学习-采样分析:实际系统同时存在场估计误差和数值离散误差,且两者可能非线性交互。论文呼吁发展联合界限以解释为什么少数步采样在某些路径上成功而另一些失败。
- 学习场的泛化与鲁棒性:训练目标只在指定路径分布下优化场(分数或速度),当采样时遇到训练分布从未覆盖的区域(如引导或条件化状态),场的行为难以预测。这一问题在离散状态空间和函数空间扩展中会更加尖锐。
- 快速采样的理论化:当前快速采样依赖启发式离散化、蒸馏和路径选择。论文提出应将其形式化为受约束的传输问题——给定NFE限值,选择路径与参数化最小化分布误差。一致性模型和一步蒸馏的尝试为此方向提供了经验基础。
- 条件化、逆问题与约束传输:将条件化解释为沿路径引入似然项,这自然提出关于稳定性和偏差的问题。Schrödinger桥提供了一种原理性路径,但将其扩展到大规模应用仍需进一步研究。
- 超越高斯欧几里得与连续状态空间:离散状态扩散、函数空间流匹配、Wasserstein流匹配等扩展表明三个设计轴在非标准空间仍然有效,但哪些理论结果依赖高斯/欧几里得假设仍需区分。
- 评估指标的改进:当前广泛使用的FID、精度/召回等端点指标可能对路径几何和求解器选择不敏感,且在高维或不同采样器间比较时存在不对称性。论文呼吁发展反映动力学稳定性、可控性和求解器敏感性的传输感知评估准则。
组会预判问答
问:论文提出的统一框架是否包含基于分数的隐式生成模型(如Score SDE)和显式速度回归的流匹配之间的本质区别?
答:论文指出二者的区别仅在于路径和学习对象的选择。在统一框架下,Score SDE学习分数场,通过概率流ODE可诱导出速度场;流匹配直接学习速度场。当所选的概率路径与前向SDE边际一致时,两者速度场重合(Proposition 3与Proposition 4)。因此,可以理解为这两种方法在理论最优意义下是等价的,差异主要出现在参数化、目标函数加权和数值求解等方面。论文通过Propositions 2和4明确了等价条件,但未在实验上验证等价性的实际边界。
问:流匹配的最优速度v(x,t) = E[ẋt | xt=x,t] 与概率流ODE的速度在什么条件下一致?*
答:当流匹配所选的概率路径与扩散模型的SDE边际分布(ρt)相同时,两个速度场等价。论文在附录D中进一步说明:条件期望v*(x,t)通过弱形式连续性方程与路径一致;而概率流ODE的vPF通过Fokker–Planck–连续性方程匹配得到。两者同为确定性传输速度,只是推导路径不同——一个从耦合和插值出发,一个从SDE时间反转出发。值得注意的是,在非扩散路径下(如整流流中的直线化轨迹),v*与vPF可能不同甚至更难直接比较。
问:论文中的误差分解是否在实际中被验证过?
答:论文自身未提供实验验证。误差分解仅是一个概念性框架。作者引用了Oko等(2023)和Zhang等(2024)关于扩散模型极小极大最优性的理论工作,以及Karras等(2022)关于时间表与离散化交互的实证分析,以说明误差源确实可分解。但在实践中,近似误差、估计误差和数值误差通常非线性耦合,难以彻底分离。这一分解更适合作为定性诊断工具,而非定量归因分析。
问:统一框架是否有助于设计新的生成模型?
答:框架的核心价值在于提供了几个独立可调的设计轴:路径、学习对象、采样动力学和目标加权。研究者可以将现有方法视为这些轴的选择组合,然后通过替换某个轴来产生新的变体。例如,将扩散路径替换为冷扩散的非高斯退化同时保持分数回归损失,即产生了物理启发的生成模型(PFGM++)。论文引用多个此类变体作为框架包容性的证据,但未提供指导如何系统性地选择新组合的准则。因此,框架对创新设计的启发仍高度依赖研究者的直觉。
本报告由立理AI生成,仅供参考,请以原文为准。