FINDER:基于深度强化学习的复杂网络关键节点发现
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Finding key players in complex networks through deep reinforcement learning |
| 作者 | Changjun Fan, Li Zeng, Yizhou Sun, Yang-Yu Liu |
| 机构 | National University of Defense Technology; UCLA; Harvard Medical School |
| 论文地址 | https://doi.org/10.1038/s42256-020-0177-2 |
| 代码地址 | https://github.com/FFrankyy/FINDER |
| 发表时间 | June 2020 |
一句话概要
论文针对复杂网络中发现关键节点(如关键节点问题CN和网络拆解ND)的NP-hard优化问题,
提出深度强化学习框架FINDER。核心洞察是利用小型合成图(Barabási–Albert模型)
进行离线自训练,学习通用策略,无需领域知识即可泛化到大规模真实网络。
方法采用图表示学习(类似GraphSAGE)编码状态,深度Q网络解码动作价值,
在合成图和9个真实网络上相比现有方法(HDA、CI、GND等)显著降低累计归一化连通性
(ANC),并在大型网络上实现20–890倍速度提升。
背景与研究动机
复杂网络中一小部分关键节点(key players)的激活或移除能显著增强或削弱网络功能。这一类问题具有广泛的实际应用:摧毁恐怖分子通信网络、设计药物靶点、灾后交通恢复、最大化信息传播(病毒营销)和最小化疫情扩散(网络免疫)等。论文将网络连通性作为网络功能的关键代理,主要关注两种常用度量:成对连通性和巨连通分量(GCC)大小,分别对应关键节点问题(CN)和网络拆解问题(ND)。
文中指出,这类问题在一般图中是NP-hard的,精确算法无法扩展到大规模网络,因此亟需一种既能保证解质量又具备可扩展性的统一方法。
现有方法的瓶颈
传统方法主要分为三类。中心性启发式(如度中心性HDA、集体影响力CI)计算简单但解质量有限,因为它们仅基于局部或准局部结构,忽略节点间的协同效应。近似优化算法(如Belief Propagation BPD、MinSum、GND)虽能获得更好解,但往往需要多次迭代或对问题结构进行专门推导,难以迁移到不同度量或加权场景。精确算法(如整数规划)仅适用于小规模图。
论文总结了三方面局限:1) 大多数方法为特定应用场景定制,缺乏通用性;2) 在效果与效率之间难以取得平衡;3) 节点加权场景(每一节点有不同移除成本)下性能严重下降。
核心洞察与贡献
核心洞察:虽然真实网络规模庞大且结构复杂,但许多真实网络具有幂律度分布(度异质性),而经典的Barabási–Albert(BA)模型恰好能捕获这一关键特征。因此,仅用BA模型生成的小型合成图(30–50节点)进行离线强化学习训练,学得的策略可以泛化到不同领域、不同规模的真实网络,无需任何领域专家知识。
主要贡献包括:
- 提出统一框架FINDER,可处理多种连通性度量(CN和ND)和节点加权场景,只需替换奖励函数即可适配新问题,对应瓶颈1(缺乏通用性)。
- 效果显著优于现有方法,在合成图和9个真实网络(涵盖犯罪、生物、通信、基础设施、社交)的CN和ND问题中,累计归一化连通性(ANC)指标均为最低,尤其节点加权场景优势突出,对应瓶颈3(加权场景性能差)。
- 计算效率提升数个数量级,在大型网络(如Flickr百万节点)上,CN无权重场景比RatioCut快约890倍,ND度加权场景比GND快约20倍,对应瓶颈2(效果与效率不平衡)。
- 离线训练一次即可通用,且可通过配置模型或重插入技术进一步优化。
方法详解
问题形式化
给定图 和连通性度量 ,目标是设计节点移除序列 最小化累计归一化连通性(ANC):
加权版本为 ,其中 是归一化移除成本。论文考虑 (CN问题)和 (ND问题)两种度量。
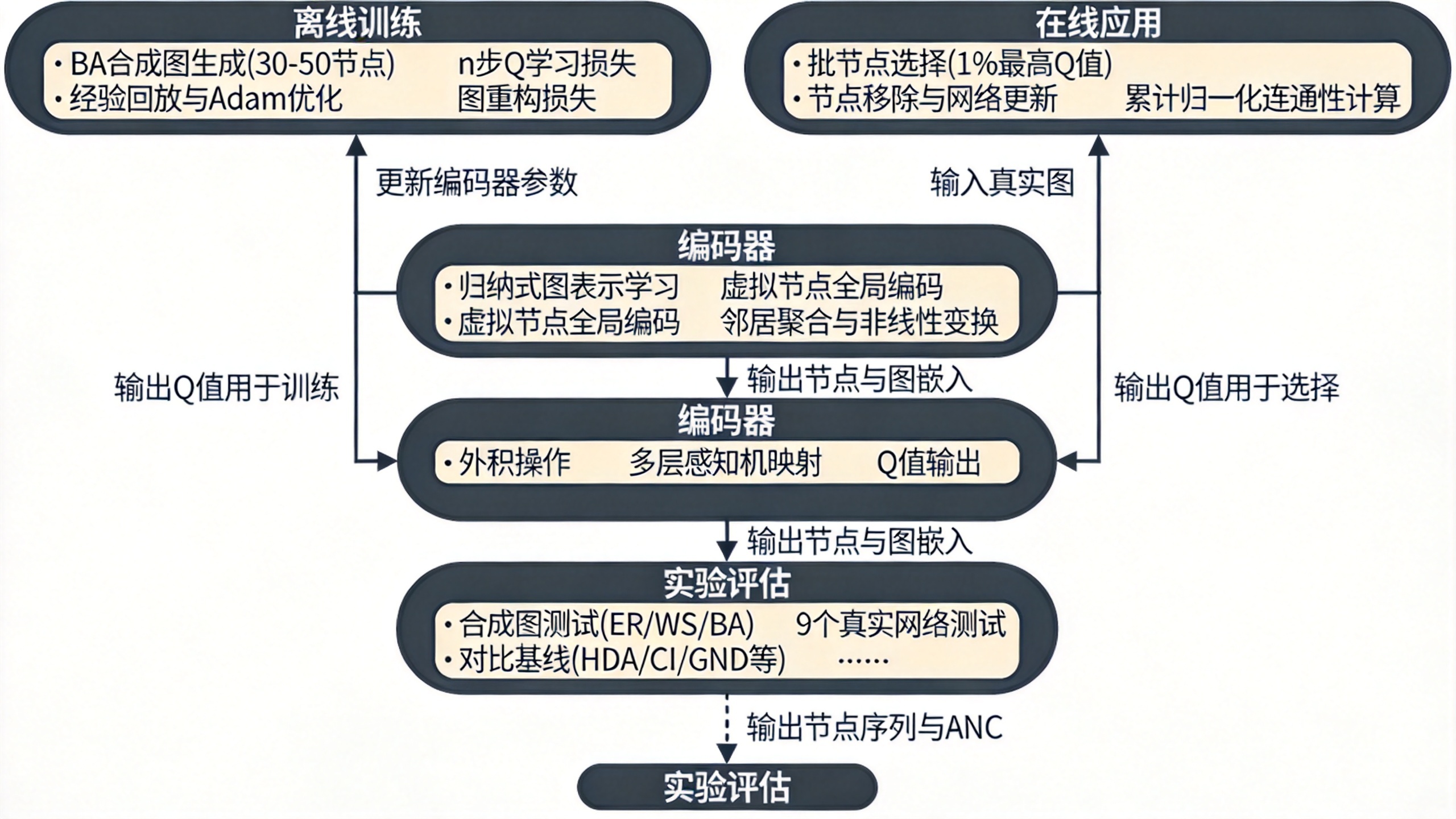
编码(Encoder)
采用归纳式图表示学习(类似GraphSAGE),将节点结构信息映射到低维嵌入。初始节点特征可以是度或移除成本。通过多轮邻居聚合与非线性变换,每个节点获得捕获结构位置和长程交互的嵌入向量。为捕捉全局图信息,引入一个虚拟节点,将所有实节点视为其邻居,经相同传播过程得到整体图的表示。
解码(Decoder)
解码部分设计深度参数化的Q函数,用于评估每个节点作为当前动作的价值。具体做法:对状态嵌入(图嵌入)和动作嵌入(节点嵌入)进行外积操作,建模细粒度状态-动作依赖,再通过多层感知机(ReLU激活)映射为标量Q值。
离线训练
训练在200,000个随机生成的BA模型小型图(30–50节点)上进行。将关键节点发现问题建模为马尔可夫决策过程:状态为残差网络,动作为移除一个节点,奖励为ANC下降。采用n步Q学习损失结合图重构损失(保持嵌入空间中的原始结构)进行端到端学习。-贪心策略(从1.0线性退火至0.05)平衡探索与利用。经验回放池容量50,000,使用Adam优化器。
在线应用
应用时采用批节点选择策略:每一步移除当前1% 最高Q值的节点(而非逐一选择)。论文通过实验验证该策略对最终结果几乎无影响,但使时间复杂度降至 ,大幅提升可扩展性。
实验与结果
评估设置
合成图:使用ER、WS、BA三种模型生成,训练集统一为BA图(30–50节点),测试集扩展到400–500节点。每种规模生成100个实例取平均。
真实网络:9个网络包括犯罪网络(Crime)、蛋白质相互作用(HI-II-14)、社交网络(Digg、Enron、Gnutella31、Epinions、Facebook、YouTube、Flickr),节点数从数百到百万级。所有网络均为无权,加权场景通过赋予节点度比例权重或随机权重构建。
基线方法:CN问题对比HDA、CI、RatioCut;ND问题对比HDA、CI、MinSum、BPD、CoreHD、GND。部分结果还补充了HBA、HCA、HPRA等。
核心实验结果
合成图:FINDER在所有规模和加权场景下ANC均低于所有基线。例如,CN节点无权重场景下,当训练和测试图均来自BA模型时,ANC值随测试图规模增大而保持最低。文中指出当训练图与测试图来自相同模型时效果最好,但BA模型训练的策略对真实网络泛化能力最强。
真实网络:以下为关键数值(均来自论文正文描述,已转化为叙述):
- ND节点度加权:在Gnutella31网络上,将GCC减至原始一半时,最佳基线HDA需约40.3%总成本,而FINDER仅需14.1%,降低26.2%成本。给定相同成本0.2时,GND使GCC保留80.8%,FINDER仅保留35.3%,改进45.5%。
- 效率对比:在Flickr网络上(百万节点),CN无权重场景FINDER耗时915秒,RatioCut需815,411秒(约890倍提升);ND度加权场景FINDER耗时7,734秒,GND需174,363秒(约20倍提升)。论文特别说明对比均在CPU上进行,未使用GPU加速应用阶段,因此FINDER的效率数据偏保守。
加权场景分析:论文对Crime网络的成本分布进行分析(仅通过正文转化)。对于CN问题,目标残差成对连通性为0.5时,FINDER识别的关键节点平均成本显著低于HDA和RatioCut。这说明FINDER学会了避免选择高成本节点,从而获得更经济的策略。
批判性评估
基线选择:覆盖了主流的中心性启发式和近似优化方法,但不包括同期基于图神经网络的组合优化方法(如S2V-DQN、GCN等)。考虑到论文发表于2020年,当时基于学习的图组合优化研究尚处早期,这一选择可以接受。但未与同样使用DRL的新方法对比是一个局限。
消融实验:论文系统比较了不同训练图类型(BA vs ER vs WS)对泛化性能的影响,验证了BA模型的最优性。还测试了配置模型和重插入技术对结果的改进。但是,对编码器内部设计(如虚拟节点的必要性、聚合层数)缺乏显式消融。一种可能的解读是,作者将更多篇幅留给了效果对比,而架构选择的内在分析可留待后续工作。
结论支撑:实验设计基本支撑了核心claim。在9个真实网络的CN和ND问题中,FINDER在所有场景下(6种×加权变量)均获得最佳平均ANC,统计显著(误差棒显示重叠极少)。效率优势在大型网络上尤为明显。但需注意,训练图规模(30–50节点)与测试网络(百万节点)的差异极大,论文虽提供了跨尺度实验(400–500节点),但缺乏对中等规模网络的精细化测试以验证泛化曲线的连续性。
优势与局限性
优势
- 通用性强:仅需替换奖励函数即可适应不同连通性度量和加权场景,且离线训练一次后可直接应用于各类真实网络,无需重新调整。
- 效果与效率兼得:在几乎所有测试场景中解质量优于传统方法,同时在大型网络上实现数个数量级的速度提升,突破了传统启发式方法的效果-效率权衡。
- 无需领域知识:训练仅依赖BA模型生成的合成图,无需目标网络的标签或专家特征。
- 代码与数据公开:提供完整代码、模型和复现资源,可复现性好。
局限性
- 泛化对训练图分布的依赖:论文表明若测试图与训练图模型差异较大(如ER/WS),性能会下降。虽然BA模型对真实网络效果最好,但对于结构特殊(如高度模块化、有向图、超图)的网络,BA模型可能不足以覆盖,FINDER的泛化边界尚未充分探索。
- 批选择策略的潜在风险:一次移除1%的节点虽然提升了效率,但可能错过最优的节点顺序,尤其在网络结构对移除顺序敏感的场景(如短程相关性强的网络)。论文声称该策略“几乎不影响结果”,但支撑实验限于合成图和少数网络,需更系统的验证。
- 加权场景中权重的定义:实验中权重设为度比例或随机值,但实际应用中的移除成本可能由多种因素决定(如保护代价、节点重要性),FINDER对任意成本分布是否鲁棒尚未验证。
- 可扩展性分析未考虑GPU加速:论文未在应用阶段使用GPU,若利用GPU,FINDER的效率优势可能进一步放大,但这也暗示CPU上的效率优势已足够显著,是实际部署的加分项。
未来方向与开放问题
论文指出可通过配置模型生成与目标网络度序列匹配的训练图来进一步提升性能,并引入重插入技术(一种后处理优化)改善结果。这些方向在补充材料中进行了初步验证,但未作为主要结果。
从开放问题角度看:1)动态网络:当前框架假设网络静态,而现实网络(如社交、交通)随时间演化,如何将FINDER扩展为在线增量学习是一个值得跟进的方向。2)其他连通性度量:论文仅验证了CN和ND两种度量,但ANC公式支持任意 ,值得探索的更复杂度量包括代数连通性、鲁棒性指标等。3)多目标优化:现实需求可能同时考虑移除成本和连通性损失,甚至涉及多个网络功能的权衡,当前框架仅针对单一目标优化,扩展到Pareto最优解集具有挑战性。4)与图神经网络架构的深度融合:当前编码器采用类似GraphSAGE的聚合,未来可尝试更强的图Transformer或消息传递变体,可能进一步提升解码质量。
组会预判问答
Q1: FINDER的训练集为何选择BA模型而非真实网络?如果直接用真实网络训练,效果会更好吗?
论文指出,使用BA模型是因为它捕获了真实网络的度异质性,并且可以在离线阶段大量生成可控规模的训练样本。如果直接用真实网络训练,可能过拟合到特定网络的拓扑细节,反而降低泛化能力。实验也验证了BA训练的策略在真实网络上效果优于ER/WS训练的策略。一种可能的解读是,BA模型提供的多样性(不同节点度、不同团簇结构)恰好覆盖了关键节点发现问题所需的归纳偏置。
Q2: 批选择策略(一次移除1%节点)的理论依据是什么?是否可能漏掉最优解?
论文在补充材料中展示了移除1%与逐一移除的ANC曲线几乎重叠(Supplementary Figs. 2–3),并在多个网络上验证了稳定性。从计算角度,批策略将时间复杂度从 降至 量级,是实用性驱动的设计。可以理解为,在强化学习框架中,Q值反映了节点的长期价值,高Q值节点集中移除不会显著改变整体策略的相对排序。但对于节点间作用高度耦合的情况(如环状结构),此假设可能失效。
Q3: 与同期基于GNN的组合优化方法(如S2V-DQN)相比,FINDER有什么本质不同?为什么不直接对比?
FINDER的核心创新在于:1)使用合成图训练并泛化到真实大图(S2V-DQN在训练图上测试,未提及大规模泛化);2)使用虚拟节点进行全局编码;3)设计外积操作的解码器而非简单的加和。不过,论文未将S2V-DQN列为基线,可能是因为后者发表在NIPS 2017,设计针对一般图组合优化问题(如最大团、最小顶点覆盖),未专门适配关键节点发现任务和连通性度量。后续工作可补充此类对比。
本报告由立理AI生成,仅供参考,请以原文为准。